Last week I was procrastinating in LinkedIn, and I stumbled upon a post about AI agents

To which I answered that I would write a blog post about this topic.
So… here it is!
Some context (pun intended)
I’ve been following the AI space really closely for the last year or so, and one thing that seems to be trending in the last months is how important context engineering is. In fact, I would say that more and more people start caring “less” about the context window (when it’s more than ~0.5M tokens more or less) as it’s clear that one-shotting is not the way to go anymore. Instead, a lot of conversations, and even companies, are focused on finding the best way to “engineer” the context of the models to achieve the best results in complex tasks.
At the same time, AI agents seem to be the way to go now. Even though MCPs got normalized, everybody is trying to find ways to build agentic systems either as a startup or as a feature in their product. You can see the latest YC batches, or the push for tools like Claude Code, Codex, Cursor Agents, etc. (in the realm of programming).
If you combine both these trends in the same canvas, what you can see is that they are highly interconnected. In fact, some of the “agents are just LLM calls in a for loop” promoters do not really apply anymore. That type of agent is “useless”.
Hence, I decided to spend some time trying to think around this crosswalk, and specifically how can a random techie build an AI agent in 2026. Yes, 2026, because 2025 agents are already outdated :D
What is an agent (in this context)?
Before going into my thoughts, let’s clarify what an agent is for me:
An agent is a process that uses AI with a set of heterogeneous tools to complete a non-trivial task in an unsupervised way.
Where non-trivial means that the task cannot be one-shotted, nor solved in a few rounds. But rather requires phases like researching, planning, analyzing and providing a clear deliverable.
How to build an agent in 2026
I’ll be brief here.
There are multiple ways to build an agent now, probably the most common one due to its immense distribution is LangChain. LangChain offers multiple abstractions to build agents, you can:
- Use the raw LLM models and build a for loop
- Use abstractions like
create_agentto build simple agents - Use
create_deep_agentto build a Claude Code like agent with filesystem and tasks
If you do not want to use LangChain, then you can go to other frameworks like the OpenAI agent framework, and the Google ADK, but probably there’s like +1k frameworks out there that offer similar functionalities.
Finally, there’s the good old way: building it yourself.
I won’t go into other tools like n8n, or similar in which you do not control 100% of the logic, in particular the code.
On how to interact with LLMs, I leave that as an exercise to the reader. And if I missed some other essentially different way to build agents, please reach out!
What about context?
If you look at all the methods to build an agent, and search on how to actually build one, everything is highly focused on how to orchestrate the code to be able to have an agentic loop. They offer more or less clear abstractions, or more utilities. In essence: they focus on DevEx and minimizing lines of code.
This is essentially wrong. Hear me out.
The real challenge (as usual) is not generating code. Having a cleaner or messier codebase should not be your main concern in regards to AI now. The world is moving so fast that spending time to have the cleaner DevEx is not worth it, when what matters is the outcome you can get. And I say this because:
- Writing code is not a bottleneck (it never was, but now even less)
- Deploying your code is almost trivial (each day there’s a new “use deploy” that one-clicks your code to the cloud)
- What your users interact with is the output of your agent, not the code
Note: If you are an OSS maintainer or someone that ships pure software, then yes, code quality matters. But for 99% of the use cases, it does not.
If we assume that 1, 2 and 3 are true, then what matters is how you can leverage the frameworks and LLMs available to get the biggest impact (a.k.a. the “wow” effect)? By taking control. And controlling this tuple can only be done by mastering context engineering. Why?
- Frameworks are just shortcuts, so it’s a matter of how to get there faster
- LLMs are out of your control, so you need to find the best one for your use case, and squeeze the most out of it
Hence, the real challenge is to optimize the connection between the framework and the LLM: context.
Different approaches into context engineering
To illustrate three basic examples using the latest tools available I decided to build three variants of agents:
- “raw”: A simple
create_agentwith an append-only message history - “summarization”: A
create_agentthat uses an auto-summary middleware to compress the message history. I used 12k context with 20 messages to keep - “intent”: A custom agent that controls the context deterministically
You can see all the code on Github.
The tools I gave the agent are the following:
list_files: List files in adatadirectory with ~1GB of NYC taxis data from 2025 in parquet fileswrite_file: Be able to write arbitrary files in thedata/contentdirectoryread_file: Be able to read files from thedatadirectoryupdate_file: Be able to update files in thedatadirectory (similar to how Claude Code does it)validate_sql: Validates SQL (DuckDB dialect) queries for correctnessexecute_sql: Executes SQL (DuckDB dialect) queries in a temporary DuckDB instance, persisted during the agent runread_docs: Access to the DuckDB documentation in Markdown format, starting from the sitemap
And the task is the following:
Using the NYC taxi trip dataset, analyze the market and create a fleet deployment recommendation analysis.
**Required Deliverables:**
You will need to create the following files with the specified content:
1. **data_profile.txt**: Document the dataset (row count, date range, key columns, any data quality issues)
2. **zone_rankings.csv**: Top 10 zones by profitability with columns: - zone_name - total_trips - total_revenue - avg_fare - avg_trip_duration_minutes
3. **temporal_analysis.csv**: Hourly performance (0-23) with columns: - hour - avg_trips_per_day - avg_fare - revenue_per_hour
4. **route_matrix.csv**: Top 15 pickup-dropoff pairs with columns: - pickup_zone - dropoff_zone - trip_count - total_revenue - avg_fare - avg_distance_miles
5. **efficiency_metrics.json**: Key performance indicators: { "best_revenue_zone": "Zone ID", "best_revenue_hour": 18, "avg_revenue_per_trip": 15.50, "optimal_distance_bracket": "2-5mi", "trips_below_min_fare": 1234, "trips_above_max_distance": 56 }
**Constraints for the efficiency analysis:**- Consider only trips with fare greater than $2.50 (minimum viable)- Filter out trips exceeding 100 miles (data errors)
Document your exploration process. Validate the CSVs and JSON can be parsed and matched against expected results.You can see that the task is non-trivial, and requires multiple steps to be solved. And it forces the agent to perform multiple non-trivial queries using DuckDB, persisting files and finally generating the deliverable: the efficiency_metrics.json.
In the evaluation, I ran multiple models with the same iteration limit (100) and exactly the same tools and files available. And I stored in the output directory the results of each run for the three agents.
Later on I compared and analyzed the results in various dimensions, specially focusing on:
- Success (either it finished the task or not)
- Accuracy (when successful, how accurate were the results)
- Context usage (total and per step)
- Latencies
- Cost
The models chosen were: anthropic-claude-sonnet-4.5, openai-gpt-4.1-mini, google-gemini-2.5-pro, openai-gpt-4.1. I chose those because they were the ones that were the fairest for all three agents. Some of the other ones I tried were:
- GPT-5: Worked but all the agents decided to stop at the end and confirm with the user to proceed
- Grok (4 and 4-fast): Struggled with tool calling, kept trying to use text output
- Gemini flash (2 and 2.5): Went super fast but struggled to come back from errors. Consistently ended in a loop and consumed all iterations
- Opus: I did not try due to pricing
How does the Intent agent work?
The key difference between the intent and the other agents is how the prompt (context) is structured. In this case, there’s a single system prompt that deterministically compresses the history of the agent, in conjunction with other relevant information for the agent to run.
Here’s a high-level view of how this prompt looks like:
Autonomous agent for NYC taxi data analysis. Complete assigned tasks by performing actions using available intents.
All actions recorded as structured intents for tracking and debugging.</role>
<history>{history_xml}</history>
<goal>{user_prompt}</goal>
<available_intents>Use the following intents to perform actions:
{tools_list_str}</available_intents>
<core_principles>**Decision Making**:- Analyze <history> and <goal> before acting (choose intents based on evidence)- Explicitly judge success/failure from outputs, not assumptions- NEVER repeat failed intents without changing approach- Learn from <recent_errors> and adjust strategy
**Best Practices**:- Explore data systematically (list files, understand schema, validate assumptions)- Document findings incrementally (create intermediate files)- Always validate SQL before executing complex queries- Use DuckDB documentation when uncertain about functions/features- Created SQL tables persist across queries - leverage this- Use ClarificationIntent to see previous outputs when needed
**File Management**:- Write files that will be accessible later for analysis- Use descriptive filenames- Reference previous work when making recommendations
**Output Requirements**:- Return ONLY JSON array of intents (no explanatory text)- Keep reasoning concise, use the `reasoning` field effectively- Make sure to include `previous_step_analysis` for context- Maintain relevant `memory` for continuity, this is KEY for you to know what you've done without re-reading full history- Use the `next_task` field to clearly define subsequent steps- Batch multiple intents when beneficial (parallelize independent tasks, or chain dependent ones), this improves efficiency!</core_principles>
<output_format>Return JSON array of intents. No text outside JSON.
The valid format for an intent is as following:
{{ "type": "<IntentSchema>_Intent", // Note that it's called "intent_args" "intent_args": {{ // Arguments specific to the intent schema, e.g. for ExecuteSQLSchema: "sql": "<your SQL query here>" }}, "reasoning": "<brief reasoning for choosing this intent>", "previous_step_analysis": "<analysis of previous step outputs relevant to this intent>", "memory": "<(optional) relevant memory to retain for future steps>", "next_task": "<(optional) clear definition of the next task to perform>"}}
So you should specially focus on choosing the correct intent schema and providing the correct arguments in the `intent_args` field!
Example:[ {{ "type": "ListFilesSchema_Intent", "intent_args": {{ "filter": "" }}, "reasoning": "Start by listing all available files to understand the dataset.", "previous_step_analysis": "No previous steps.", "memory": "", "next_task": "Identify relevant files for taxi trip data." }}, {{ "type": "ExecuteSQLSchema_Intent", "intent_args": {{ "sql": "SELECT COUNT(*) FROM trips" }}, "reasoning": "Count total number of trips to get an overview of the dataset.", "previous_step_analysis": "Listed files and identified 'trips.parquet' as the main data file.", "memory": "trips.parquet contains NYC taxi trip records.", "next_task": "Analyze trip counts by day." }}]</output_format>You can see that there are some Python f-string placeholders, which are the dynamic parts that change in each iteration of the agent. If you want to see all the details, here’s the code for the intent agent prompt.
Results
Success rates
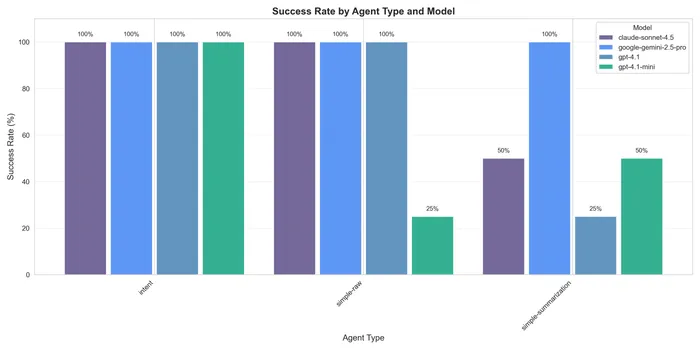
The most important thing to check first is success rates. I.e., did the agent finish the task or not? For that the “intent” agent scored a 100% rate in all models and all runs. The second best was the raw with only flakiness in GPT-4.1-mini, and the last one with pretty bad results was the summarization one.
Accuracy
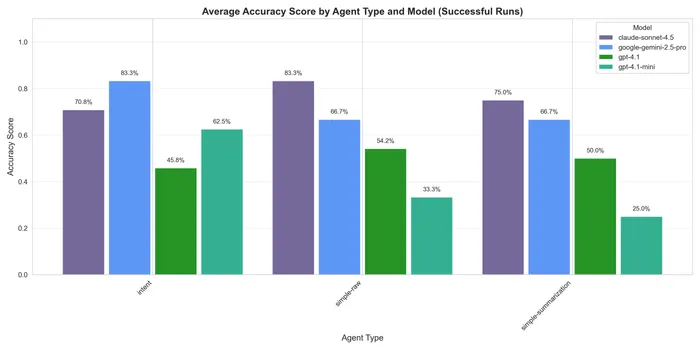
The accuracy was not the best in general, probably due to the models used. However you can see that the intent one scored consistently higher across models than the other two, which were pretty close to each other, in fact they followed similar patterns, being the summarization one slightly worse.
Context usage
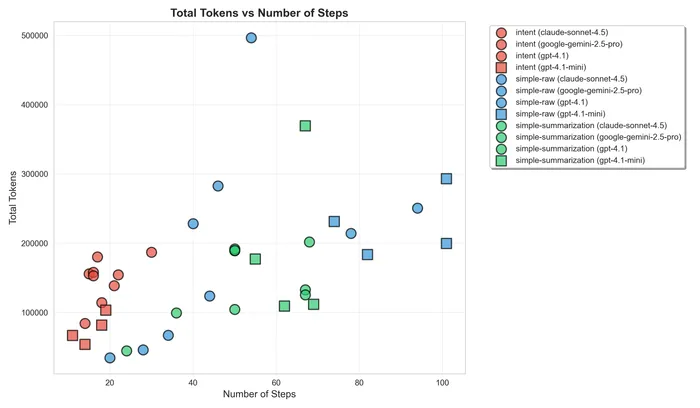
Before checking the result in terms of context, I want to note how much steps each agent needed to finish the task, which surprised me:
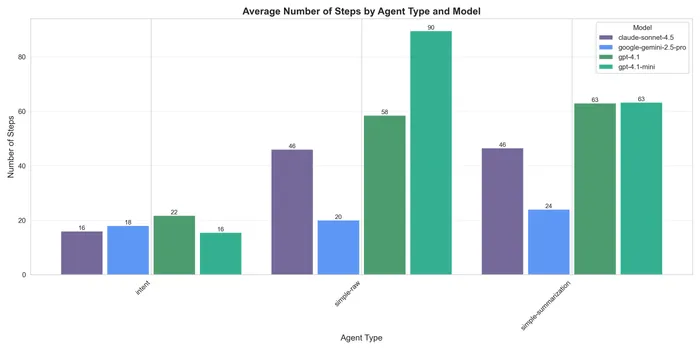
The intent one is consistent even across models and much less than the other two (fewer than 25 steps).
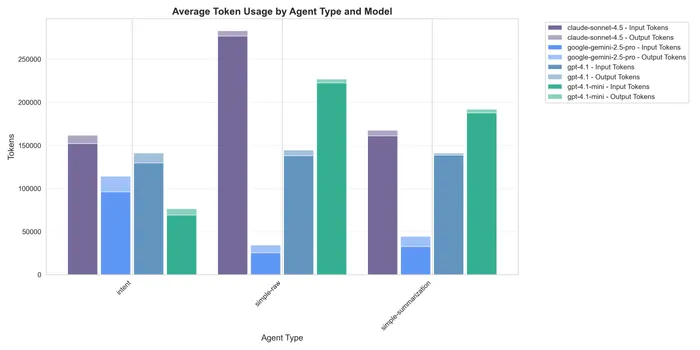
Now in terms of context usage, I analyzed the token usage, both for input and output, and the results showed a clear difference in the raw one, being the highest, and the summarization and intent being pretty close.
Latencies
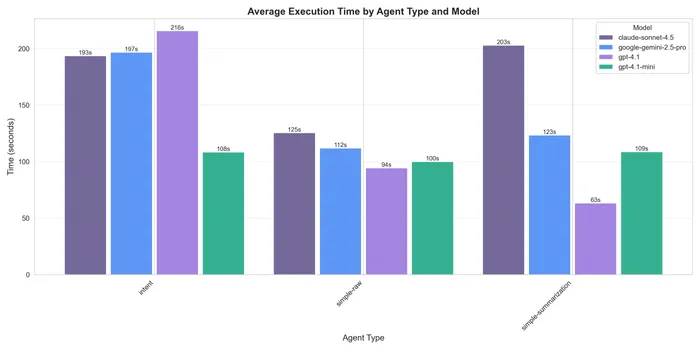
The intent one was the slower one. I used OpenRouter and generally the latencies might not be super consistent. In general all were able to finish in less than 4 minutes.
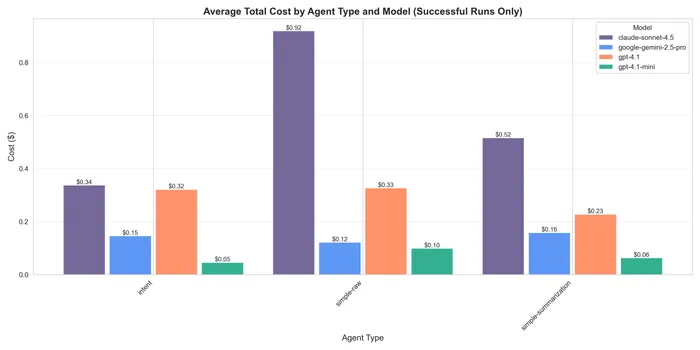
Cost
Finally, I will mention the cost, in which obviously the raw one won, and then the summarized one was pretty close to the intent or even cheaper. This is not surprising due to the nature of summarization being a plateau in terms of context limits.
Full report
You can see the full report on Github.
How the results relate to context engineering
So… what can we learn from the results above? It might seem confusing, as there’s no clear winner in all categories. But it is: the intent one is the best one. Why? The goal of the user was to get a specific deliverable, and the only agent that managed to (100% of the times) deliver it was the intent one.
Let’s break down each metric, focusing on latency and cost first.
In terms of latencies, I saw a difference in the unit of ~60s, which for an agentic flow is nothing. These flows are meant to run in the background, or even when running interactively the users are used to +10m wait times for things like the ChatGPT or Claude deep research anyways. It was never about sub-second latencies anyway.
On costs, the difference is really between the summarization and the intent one, as the raw one was the more expensive one. Now taking into account the inconsistent success of the summarization anyone would want to pay a few dollars more for a guaranteed success.
Ok, now what about accuracy? To be honest, and this is purely from my experience, accuracy has more to do with the model than anything you might be able to control. You can see that the more expensive models are the best, that’s it.
Now that we cleared these out, let’s talk about context!!
Raw
The raw agent is the simplest one. It just appends context on each turn, and the agent is able to see the full history of what happened. This is good for small conversations, but as the number of steps increase, the context becomes noisy, and the model struggles to find the relevant information (needle in a haystack problem). This is specially true when the model has to deal with errors, or complex reasoning.
In this particular user task, I made it so that adding to the stack is expensive, as you would be calling tools like write_file or execute_sql that would generate a lot of context. Hence, the model would struggle to find the relevant information in the context, and would often forget what it was doing, or make mistakes.
So no surprise that the raw agent ate the most context of all.
Summarization
This one is pretty similar to the raw agent, but after hitting a threshold (12k tokens in this case), it would summarize the context to compress it. This is good in theory, as it would reduce the noise in the context, and help the model focus on the relevant information. Nevertheless, in an analytical task like this one, where a number going a unit up or down matters, summarization can be harmful, as it might lose important details.
In particular, I had to adapt the default summarization strategy to force the summarization model to keep the original user task, as I saw that by default it would completely hallucinate and forget what the user wanted to achieve. This may be improved by using a better summarization model, but it would incur in added costs and no real guarantees.
On the good side, the context is capped, so you can “fine-tune” the summarization threshold to optimize performance for the type of tasks you want to solve, but my guess is that it would require a lot of testing, tuning and dependence on the type of user task (e.g. if the initial task automatically exceeds the threshold, then it would be useless).
Intent
Finally the intent approach. This is a completely custom LLM history approach. The idea is pretty simple: distill what the agent’s essential goal is, and write down a “prompt template” that you overwrite on each step with your progress (see the code for the prompt here).
This, obviously, is more tedious and has a default context bump, as the template might be larger than a simple system prompt in the first two agents. Also, it will grow with time, as you add more and more steps.
The good thing, as you can see, is that it generally requires less steps due to the deterministic compactification, and is scaled more linearly than the raw approach.
Conclusion
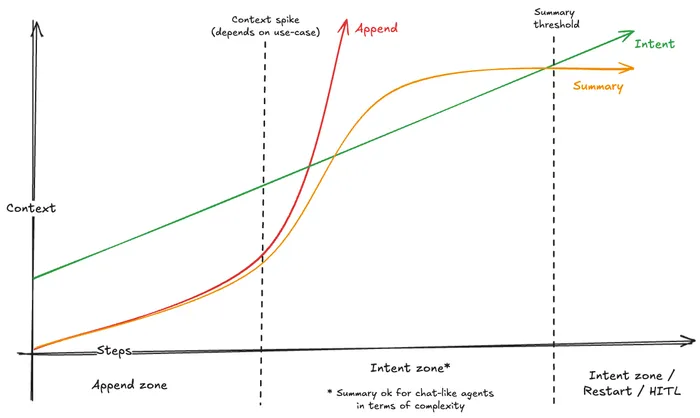
The conclusion is pretty simple: context engineering (control) matters. A lot. The more you control the context, the better the final results you will get.
In particular, I wanted to summarize the three strategies analyzed in the following charts.
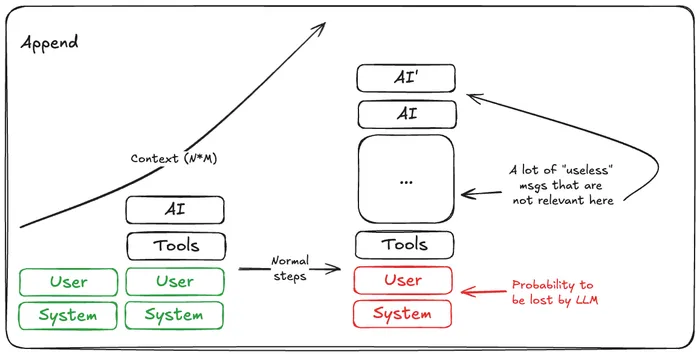
As simple as that, the more to dump into it the less you will get out of it. That’s why Claude Code has auto-compactification.
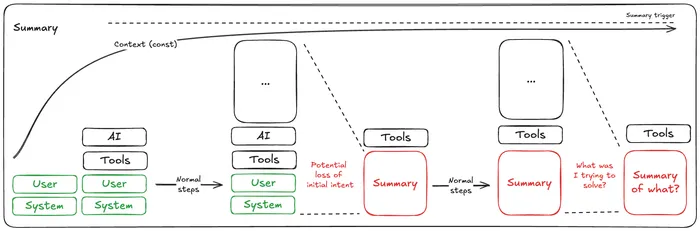
In this case, it’s clear. The kids game of the broken telephone. The more you summarize, the more you lose. Maybe after the 4th summary you do not even know what the original task is, so probably 42, right?
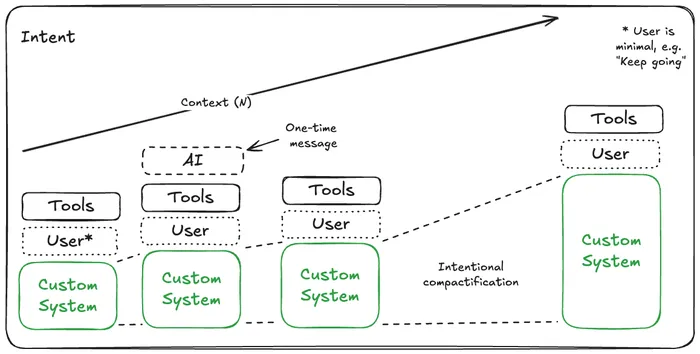
And this is the proposed intent approach. Simple, but effective. The more you control the context, the better the results. But, as usual, it will grow, so it also has it’s limits, yet more controllable and higher ceiling than the other two.
Ok… what should I do then?
As usual, there’s no “silver bullet”. However, I would recommend the following:
-
If you have a simple agent, just go for the raw approach. It will work fine. If you do not need a lot of tools, and just want to iterate a few times to get a result, it will be more than fine.
-
If you are building a more complex agent, then I would recommend going for the intent approach. It will require more work, but the results will be worth it.
-
If you are building an extremely complex flow, then you should probably consider splitting, or having a Human-in-the-loop (HITL).
Next steps
If you read this to this point, I love you. If you disagree with me, I love you even more and please reach out to me to discuss!
Personally, I find this context engineering topic super interesting and as something that evolves so fast, maybe this post will be useless in a month, who knows.
But, here’s a few things that I want to explore next:
- Figure out if there are context driven libraries. To start, I found this in the LangChain docs: https://docs.langchain.com/oss/python/concepts/context#dynamic-runtime-context
- Check out how context and agent getting better coding come into play together to make complex tool call chains easier with code: https://www.anthropic.com/engineering/code-execution-with-mcp
References
Here’s a set of references I found extremely useful in the last months, and during the writing of this blog: